

The project aims to design an urban space where essential activities like “Live, Work, Grow, Store, Sell” are interconnected, resembling a neural network empowered by machine learning. This approach seeks to create a dynamic and efficient environment where these activities complement each other, fostering sustainability and adaptability within the urban context.
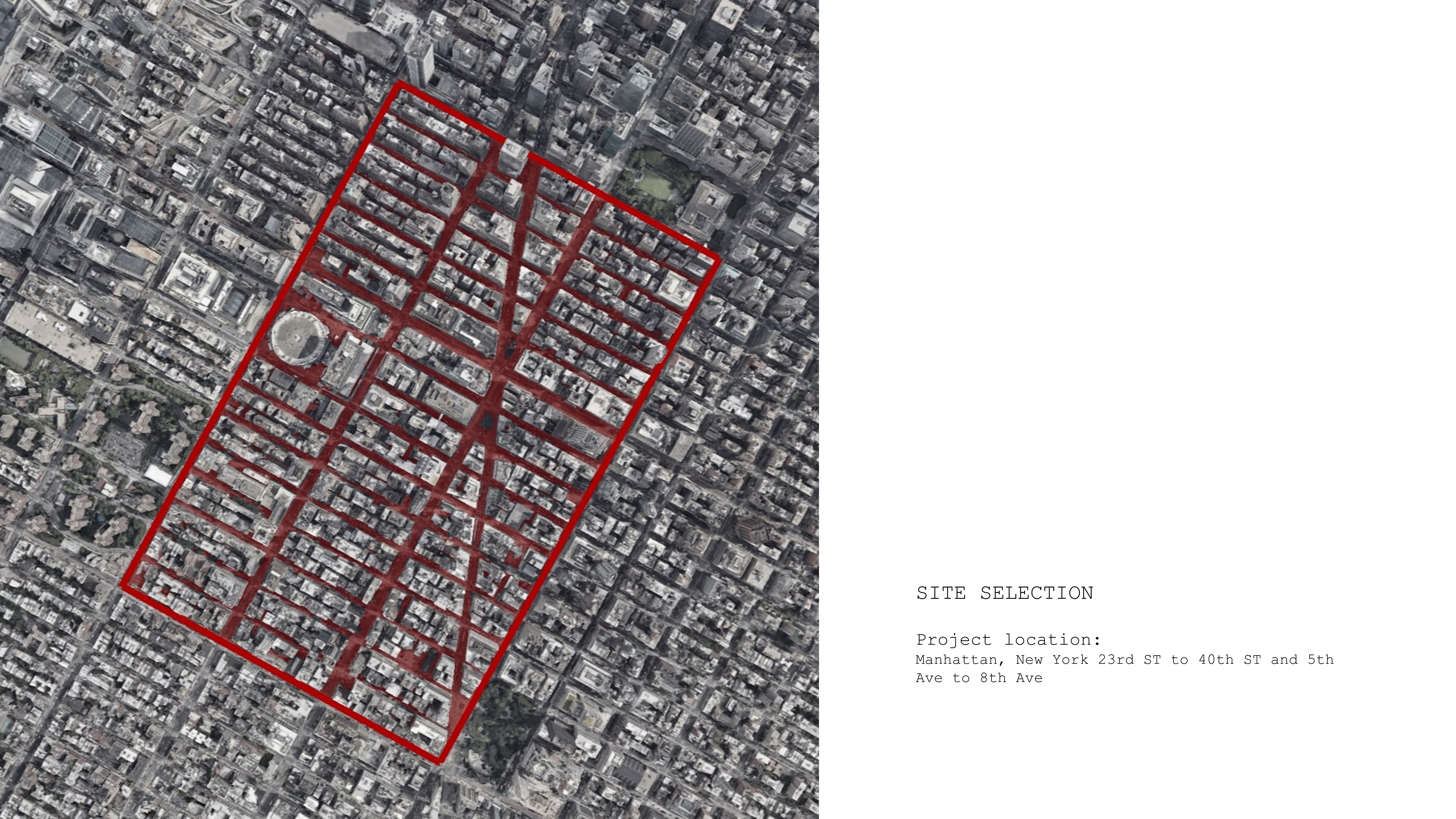
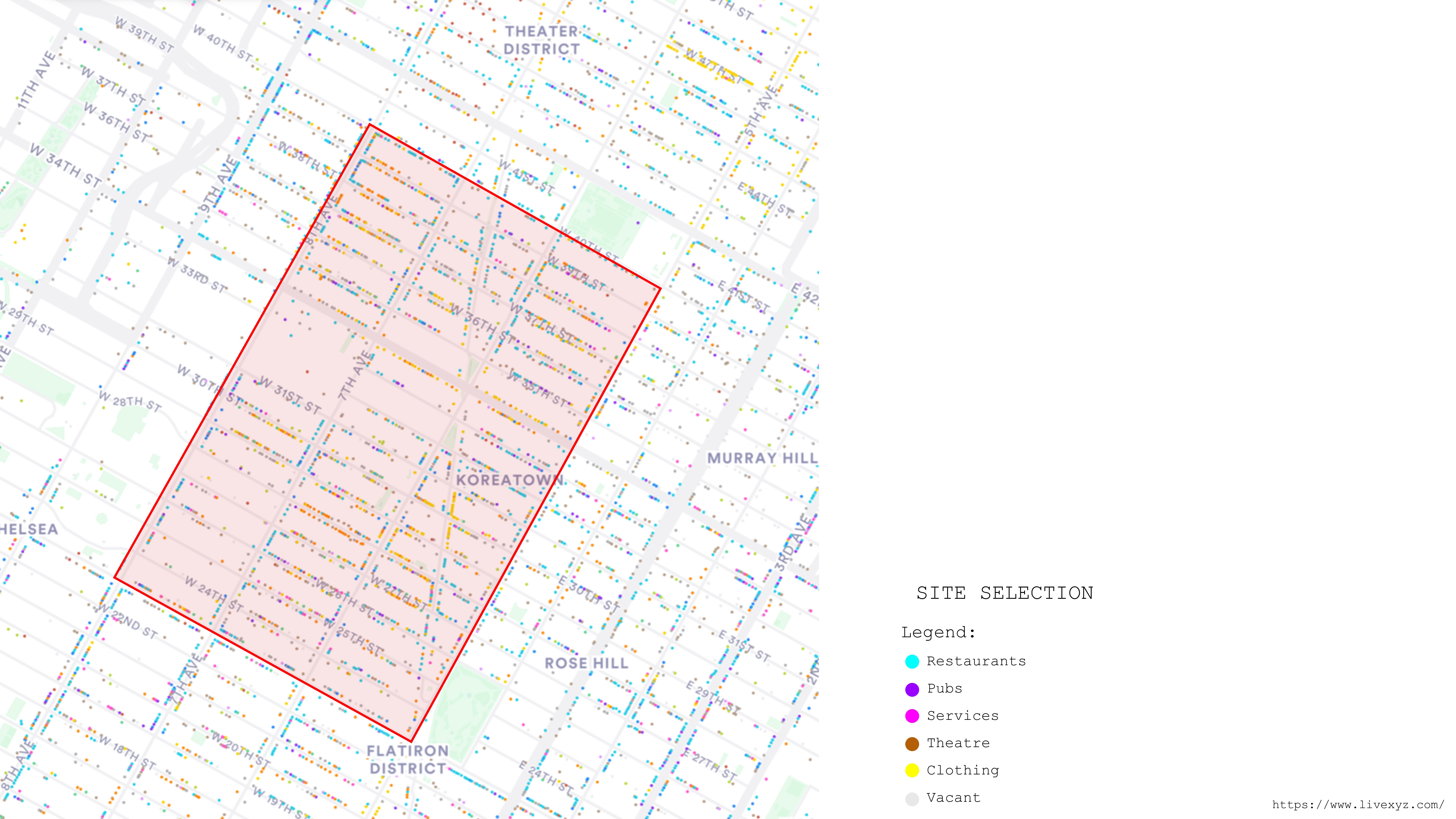
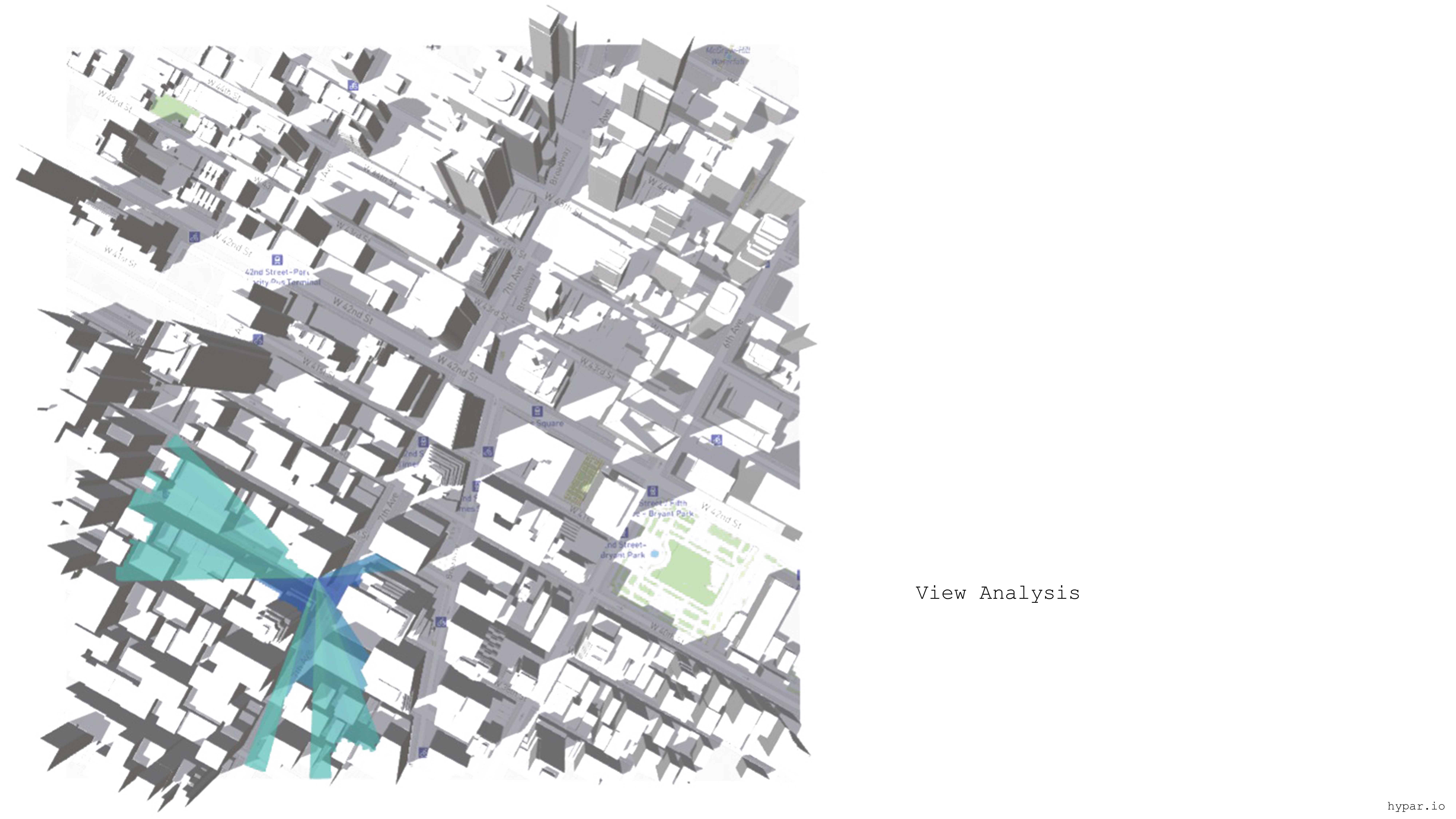
In accordance with the City of Yes proposal, our initiative targets the repurposing of vacant office buildings in New York City, with a particular focus on the Garment District due to its significant inventory of unutilized office spaces. Our initial phase involved thorough research into the current conditions and occupancy status of each building within the area, laying the groundwork for strategic redevelopment efforts aimed at revitalizing this urban district.
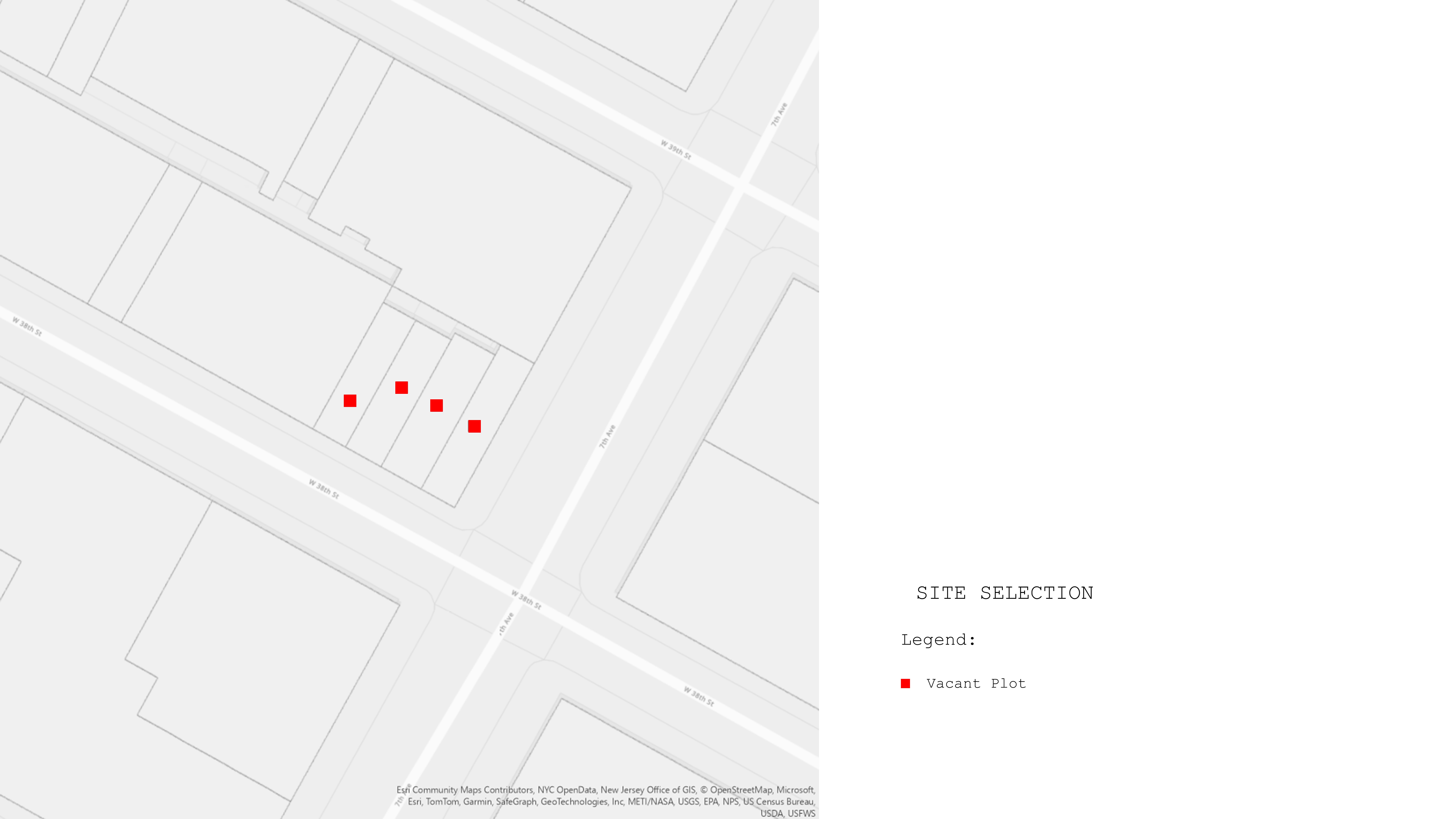
Through the utilization of Geographic Information System (GIS), we identified four buildings within the Garment District surrounded by taller structures, resulting in a lower Floor Area Ratio (FAR) for these buildings. This discrepancy in FAR creates challenges with natural light penetration, adversely affecting the quality of the indoor environment.




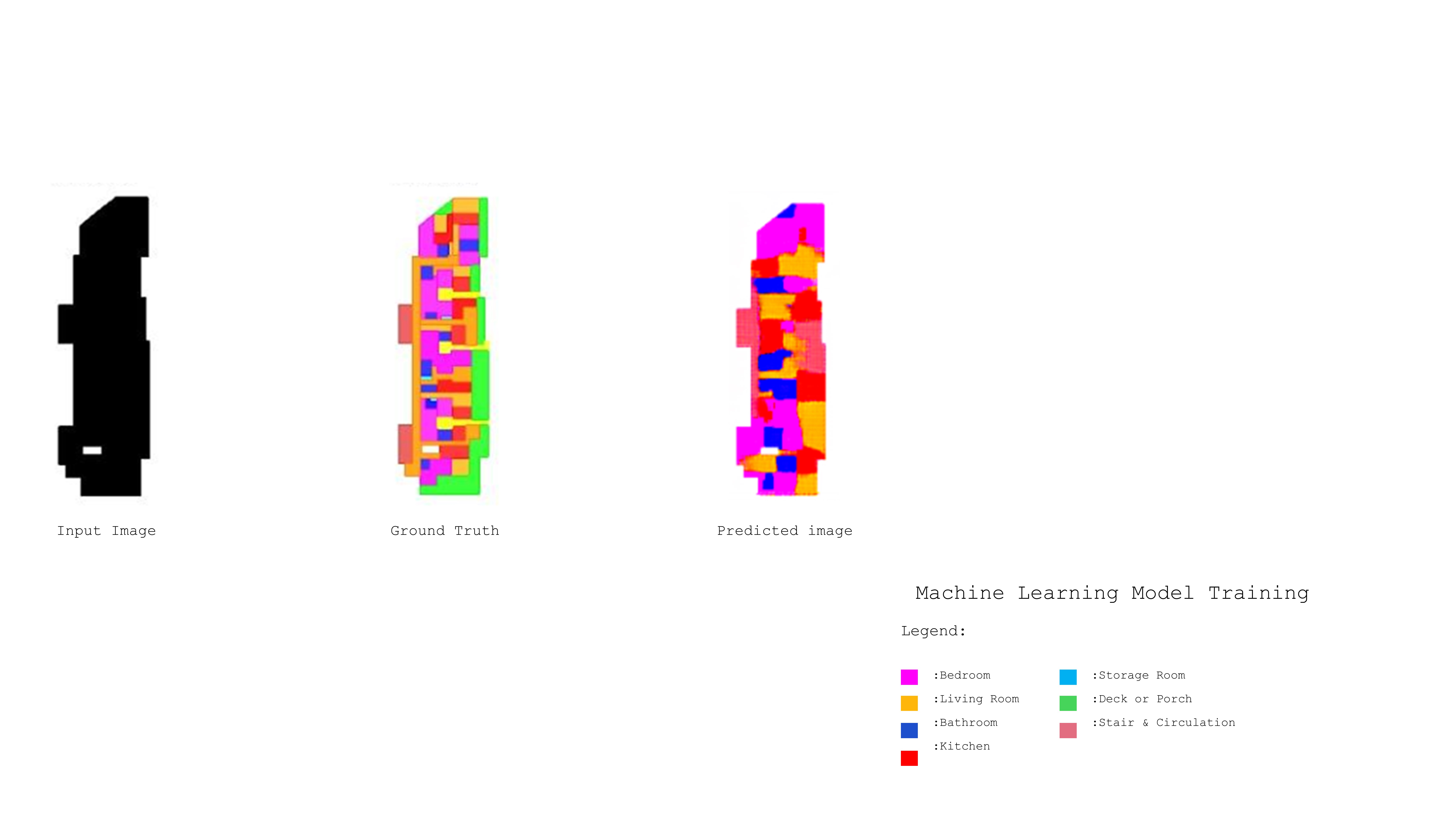
Being part of our class, pix2pix is a conditional generative adversarial network, that takes an input and outputs a result based on the dataset that it was trained on.



Taking the algorithm a step further, and integrating the concept of light into our process, we started gathering crystal images, desaturating and contrasting them, forming a dataset out of it.




The final output was the result of 2 models. Model 1 outputs an image that translates the behavior of light on a crystal, Model 2 translates a relationship of colored pixels based on the dataset that it was trained on.
Then the output of model 1 is used as an input in model 2 to generate a new output.
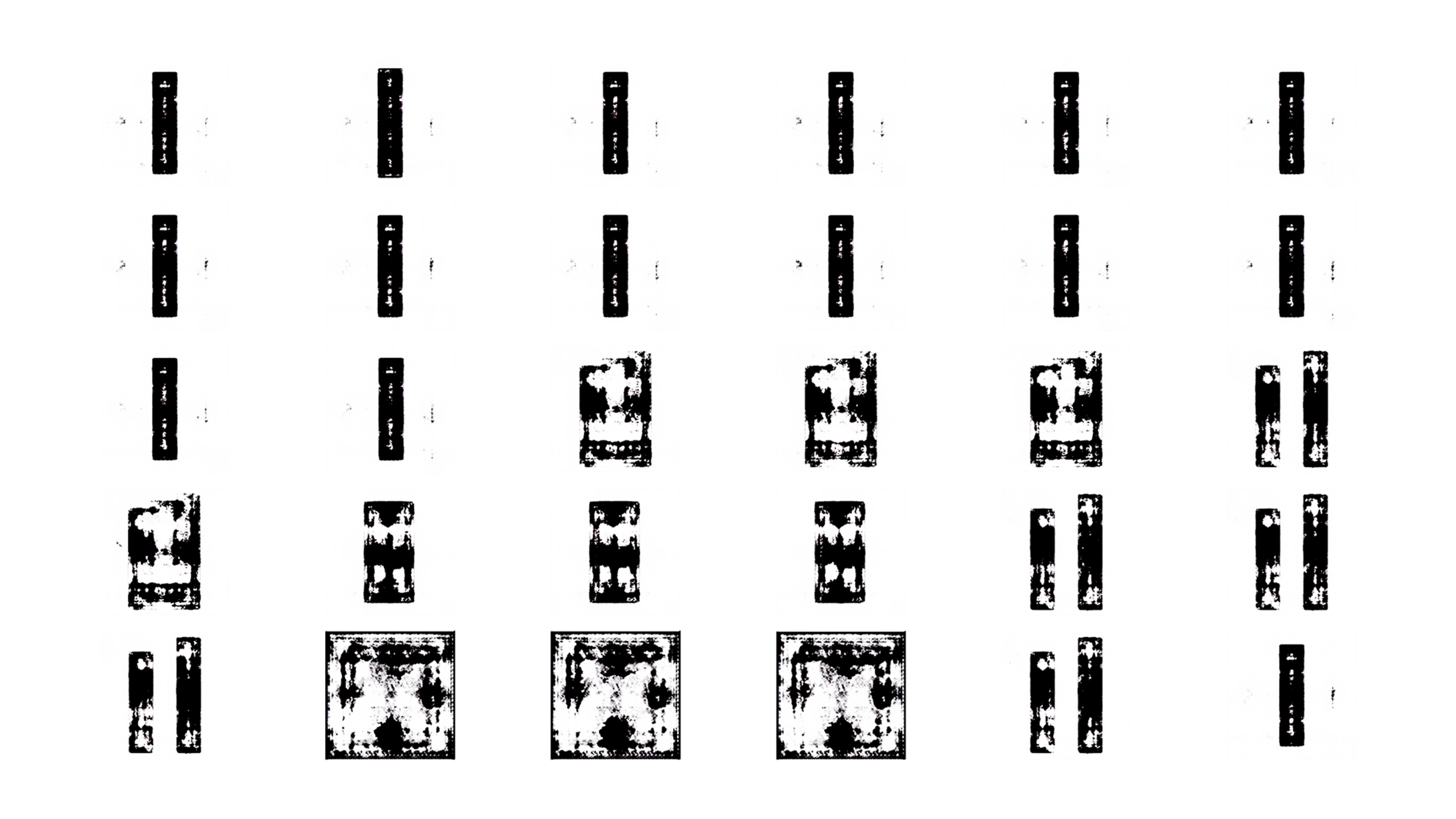
Dataset Generated using Model 1

Dataset Generated using Model 2



The process demonstrates the transformation of a 2D image into a 3D model by first generating a depth map that interprets the distances of different parts of the image from the camera. This depth information is then used to construct a textured 3D model that retains the color details of the original image.




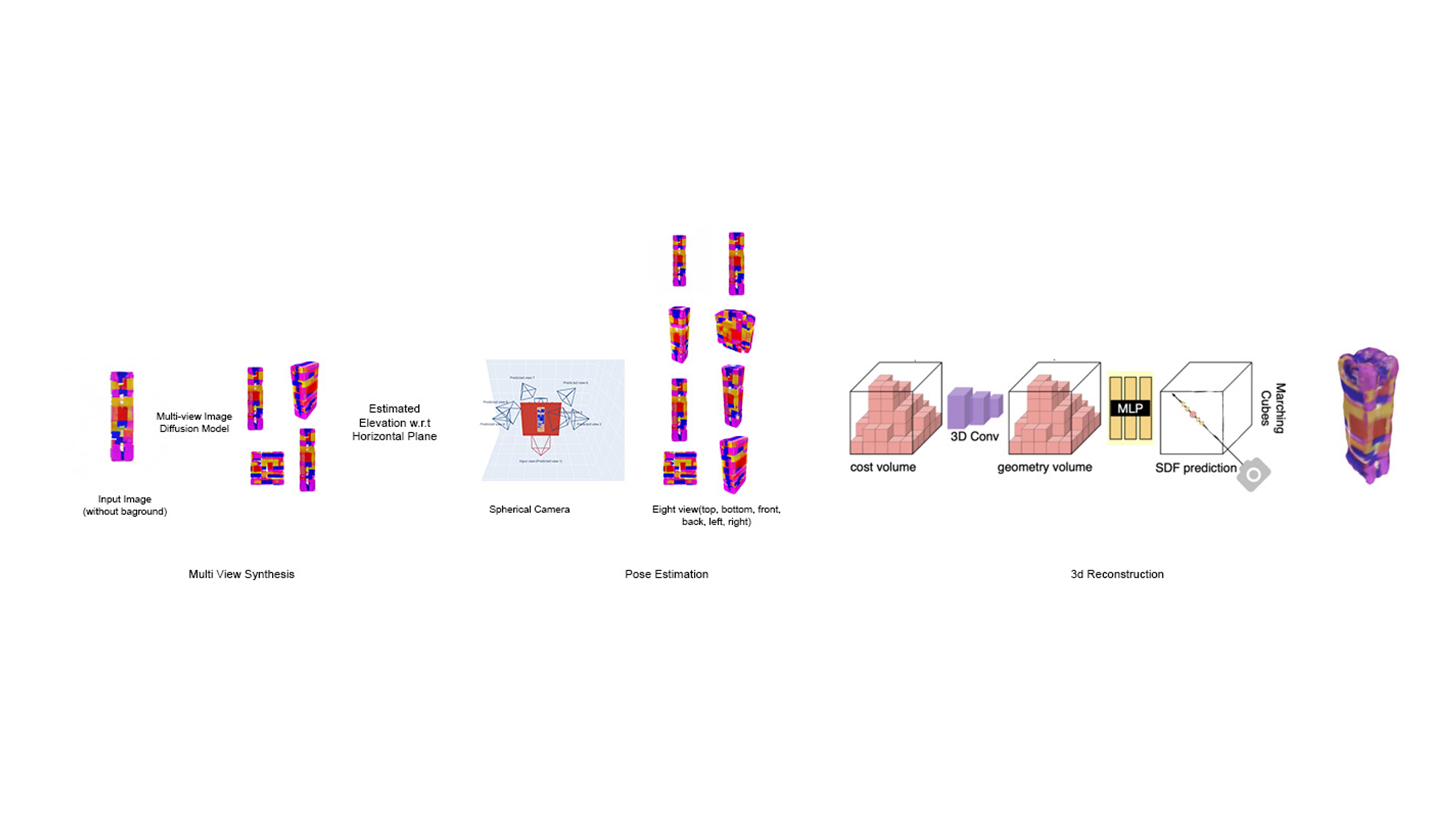
This process transforms a 2D image into a 3D mesh model by first generating multiple views using a diffusion model and then synthesizing these views from different perspectives to estimate the object’s pose. The 3D structure is reconstructed using a combination of cost volume analysis, 3D convolution, Multi-Layer Perceptron for Signed Distance Function prediction, and the marching cubes technique to create a detailed mesh model.
https://drive.google.com/drive/folders/1P3SWs4h1ouful2UsQSIopjJOX7b0u7A1?usp=sharing

The left bottom image depicts a schematic representation of different views of an object, explaining how various views are predicted from a single view. Each image displays the object from various perspectives, showing synthesis to help in constructing a 3D model.



The Convolution Reconstruction Model (CRM) transforms a single 2D image into a 3D textured mesh by first generating multiple orthogonal views through a diffusion model. It then maps each pixel to a 3D coordinate using Canonical Coordinates Maps (CCM), providing spatial information for each view. Finally, a convolutional U-Net processes these mapped views to reconstruct a detailed 3D model of the initial image.
https://drive.google.com/drive/folders/1uA-HR6a-GtADH6k7yOA8hkPU-1Nzr7Id?usp=sharing




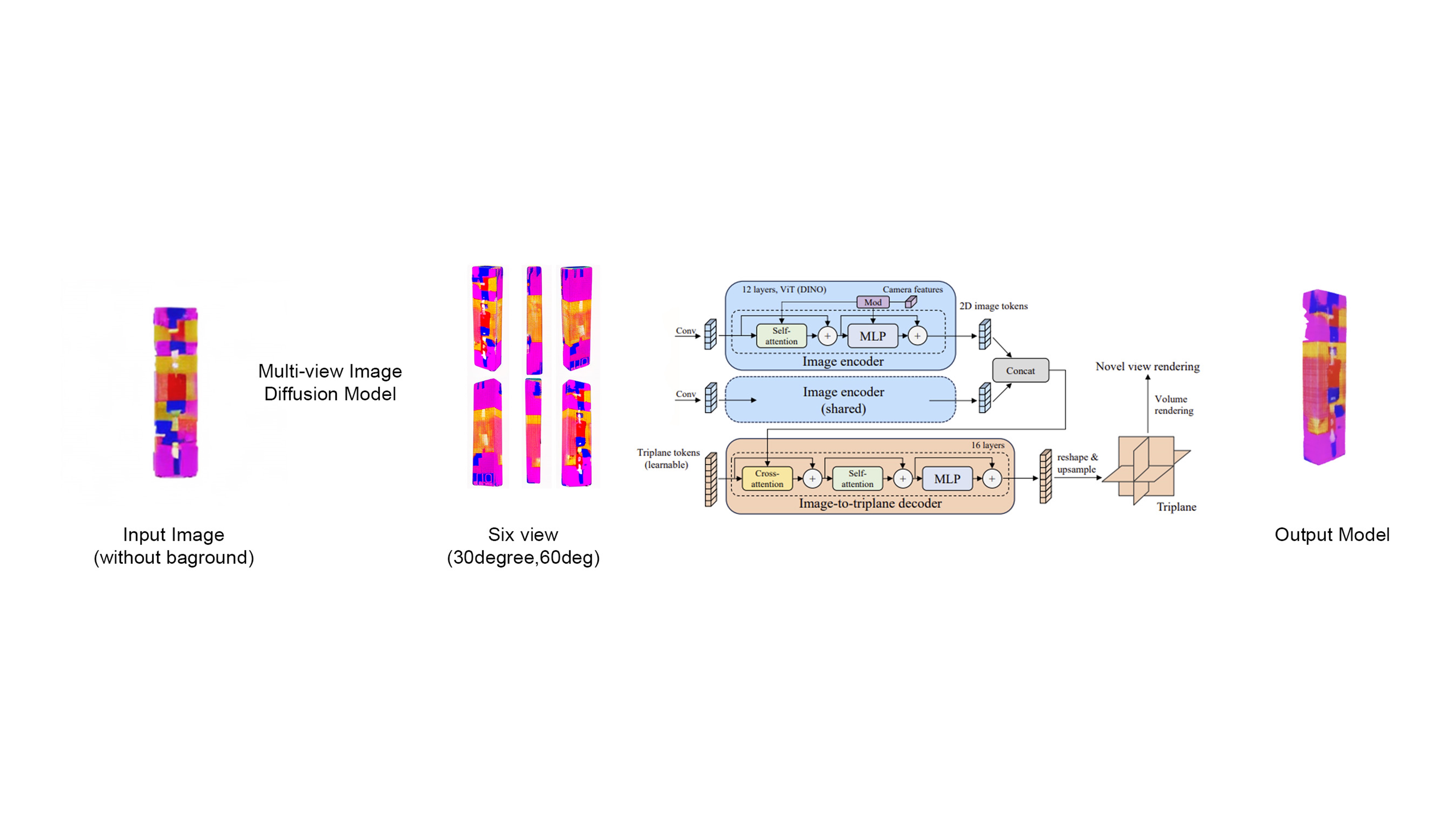
Instant Mesh generates a 3D mesh from a single 2D image by first creating multiple views of the target object using a multi-view image diffusion model. It employs an advanced pipeline involving image encoding with Vision Transformers and MLPs, followed by a conversion of image data into triplane tokens for depth and spatial analysis. The process culminates in a detailed 3D model, synthesized through novel view rendering and volume rendering techniques.
https://drive.google.com/drive/folders/1IaFfxhZ0lZmPljEttRVassaIruRsSDW9?usp=sharing


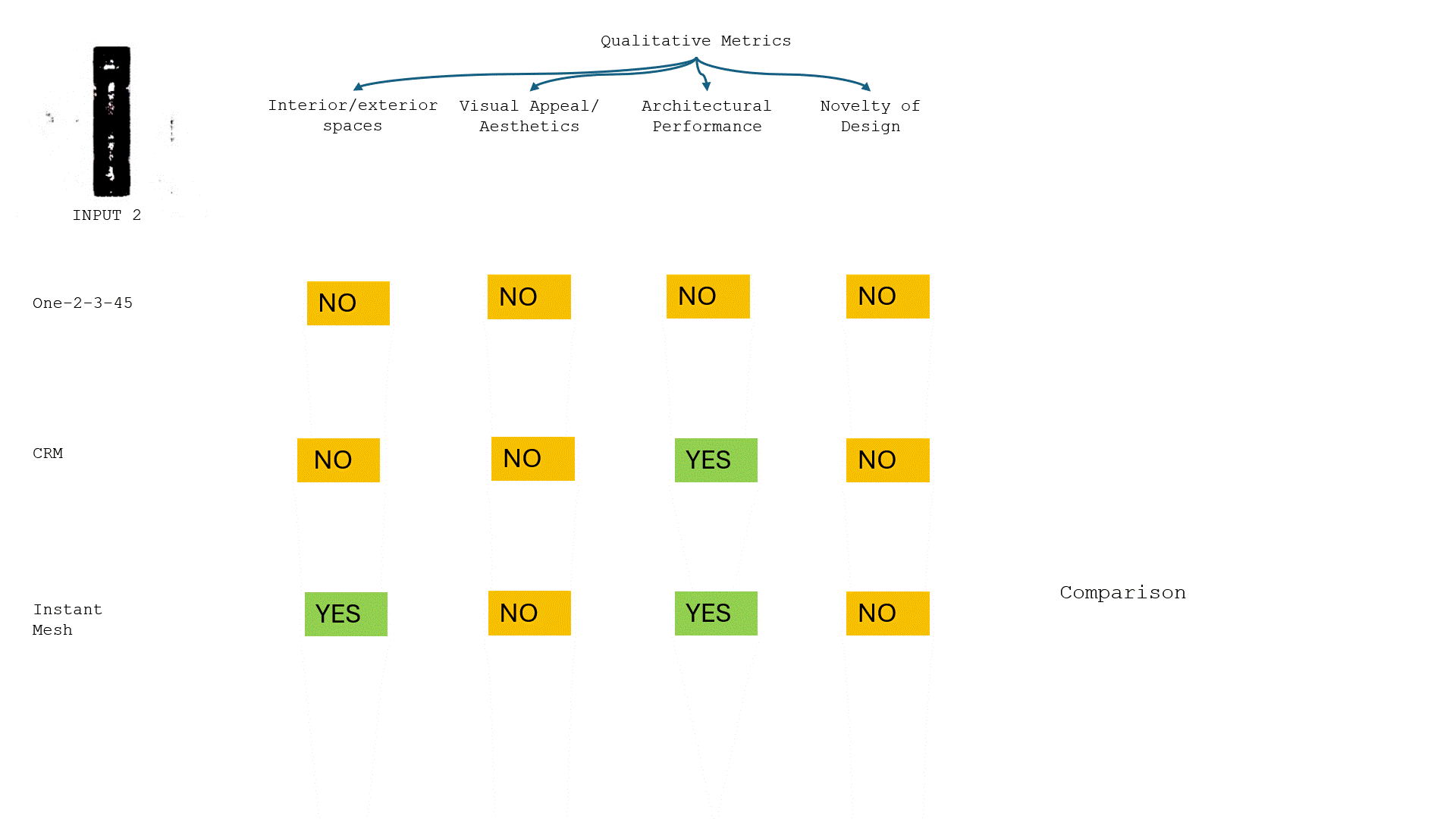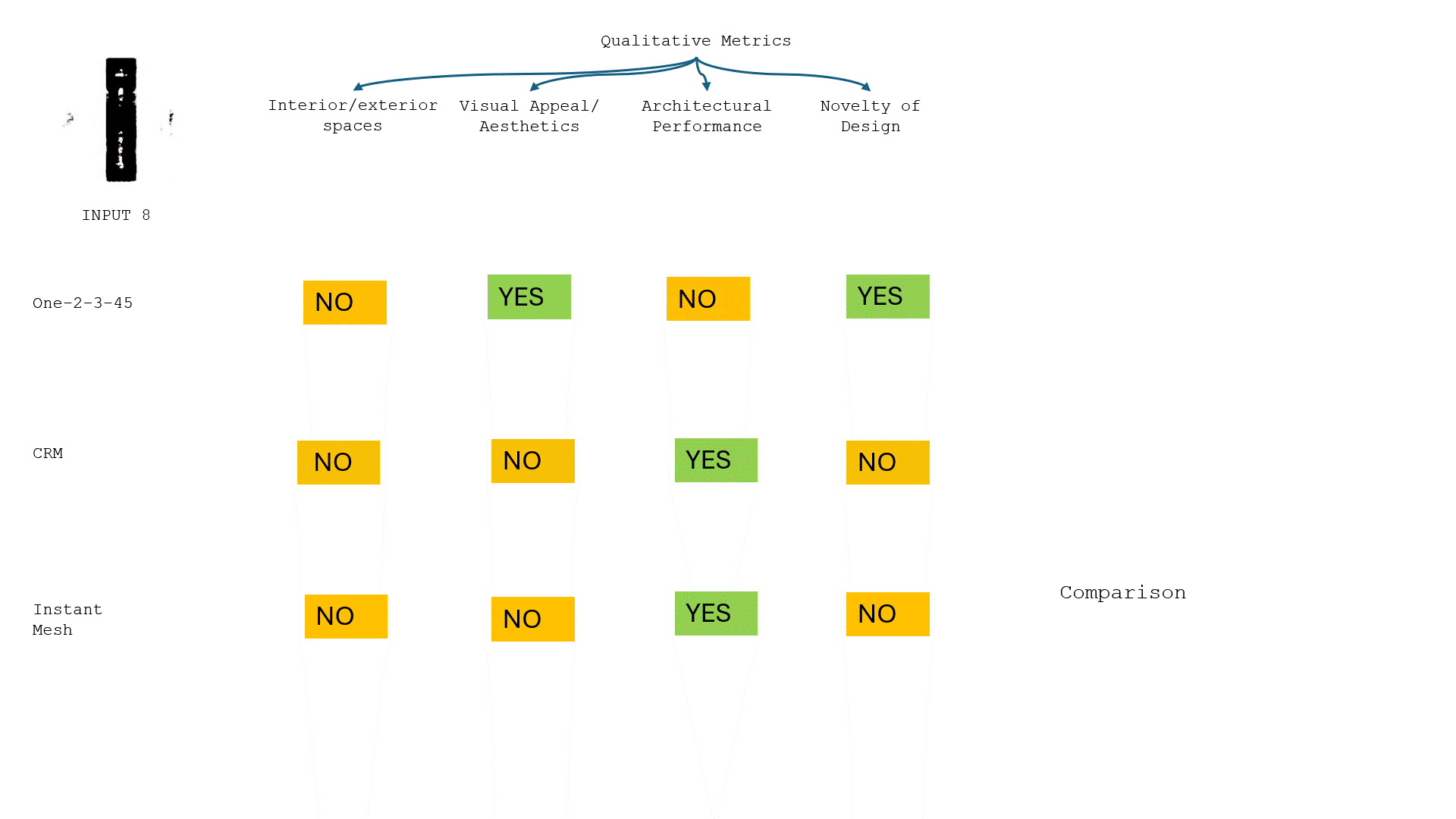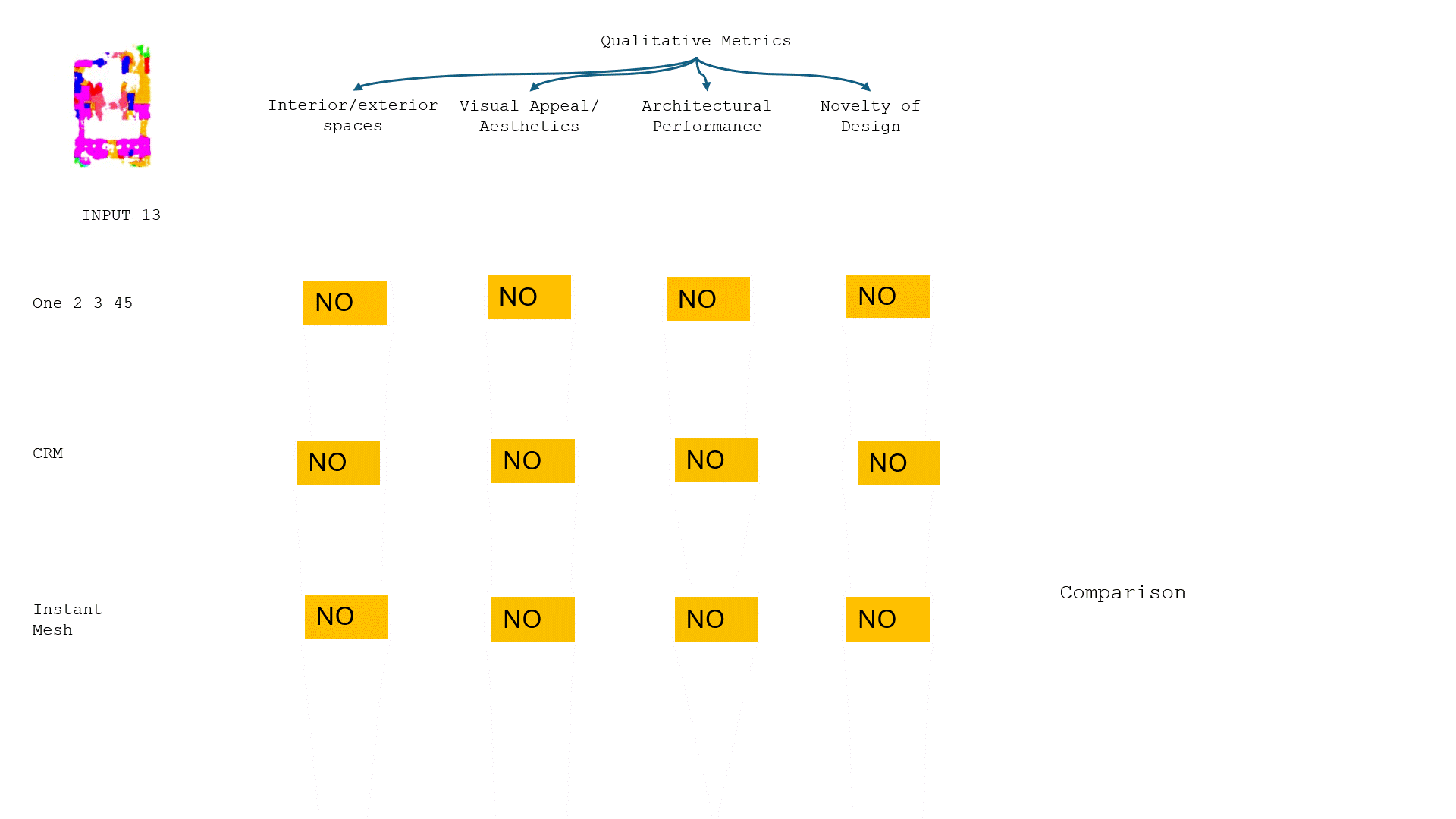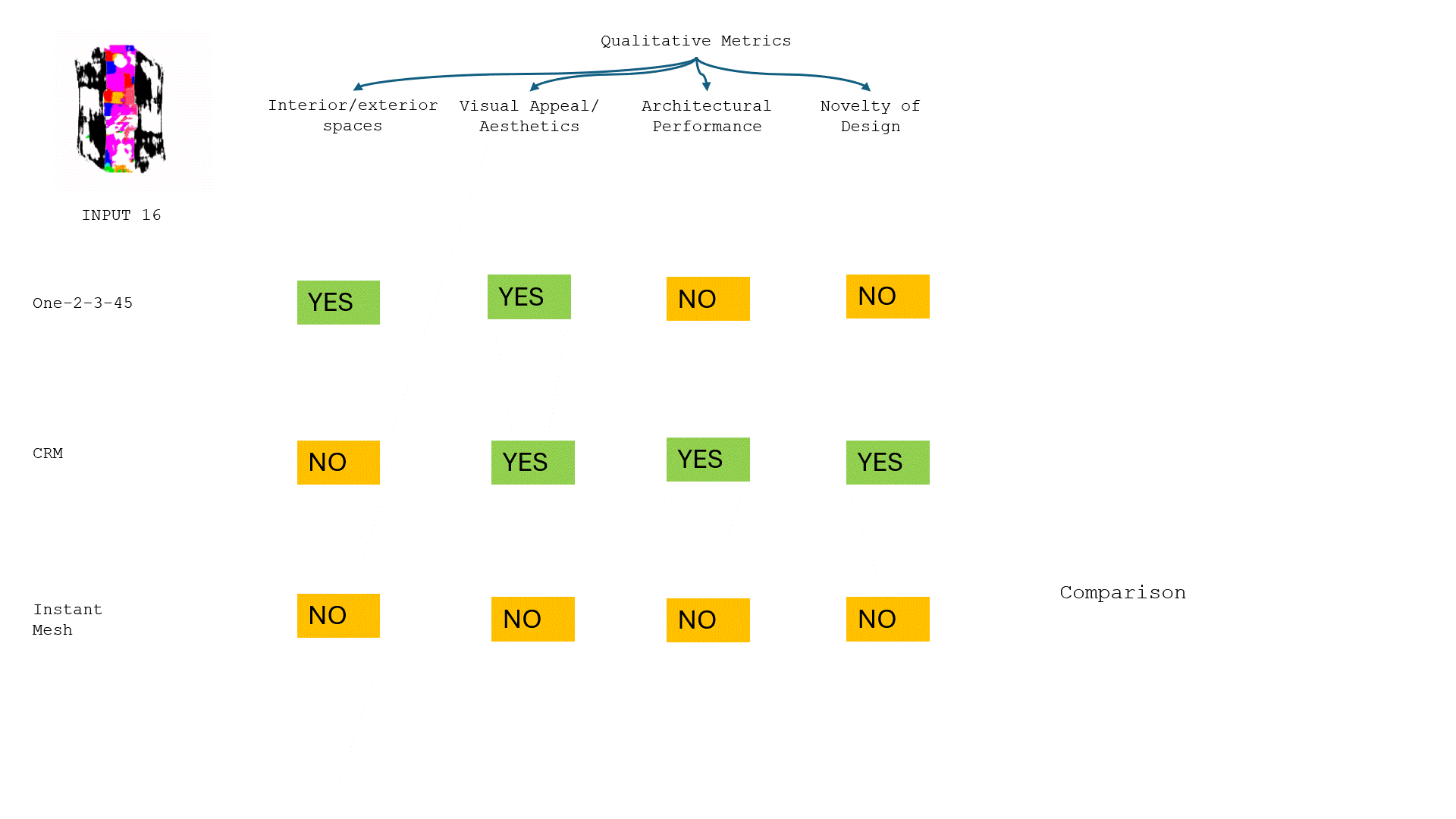


Following the concept of using crystal structure within architecture, we started with a crystal image of our choosing.

Using Image to Mesh model, a surface was formed from the provided crystal image, which was then placed within the selected site

Front Elevation

Section
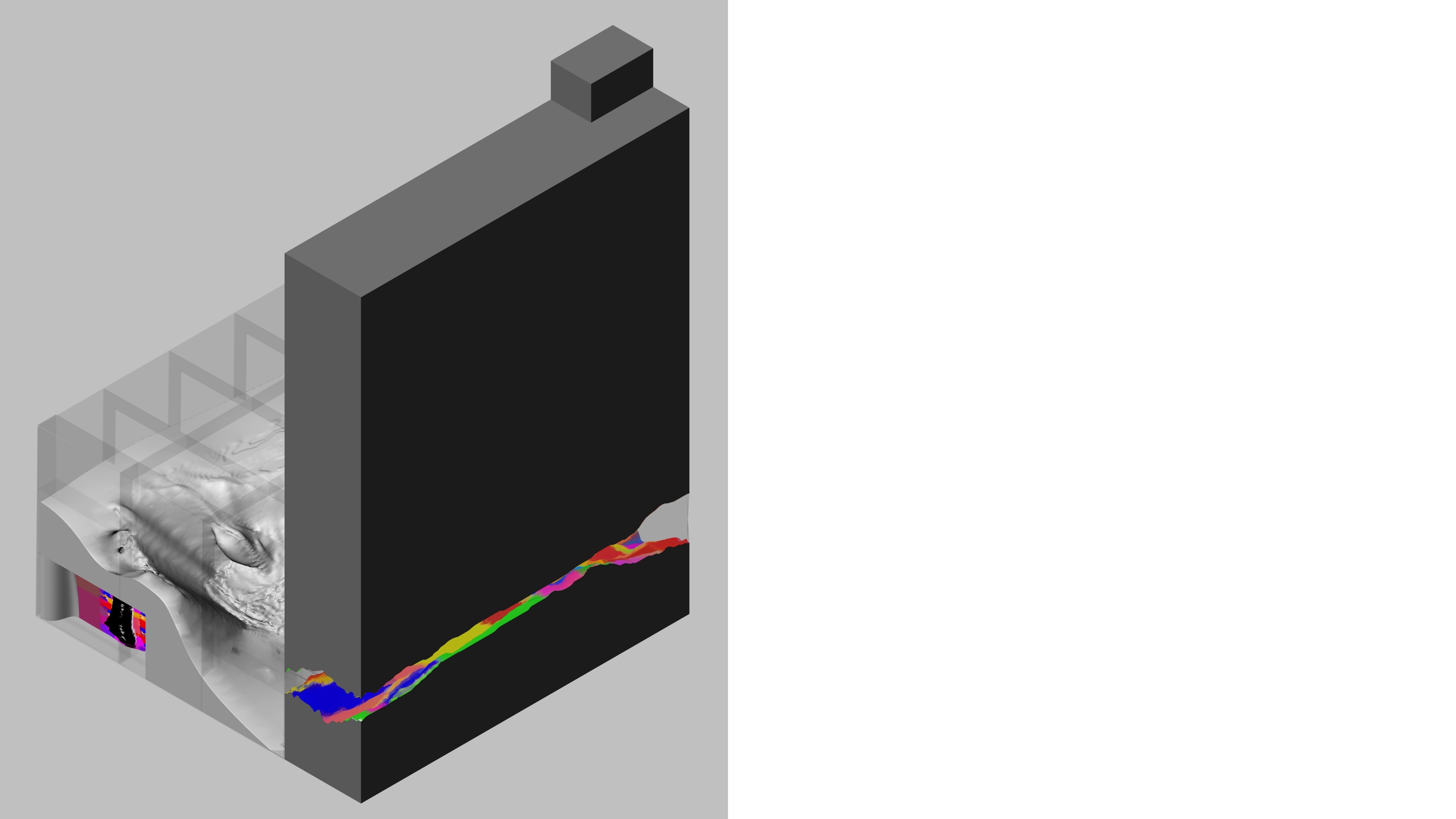
Isometric View
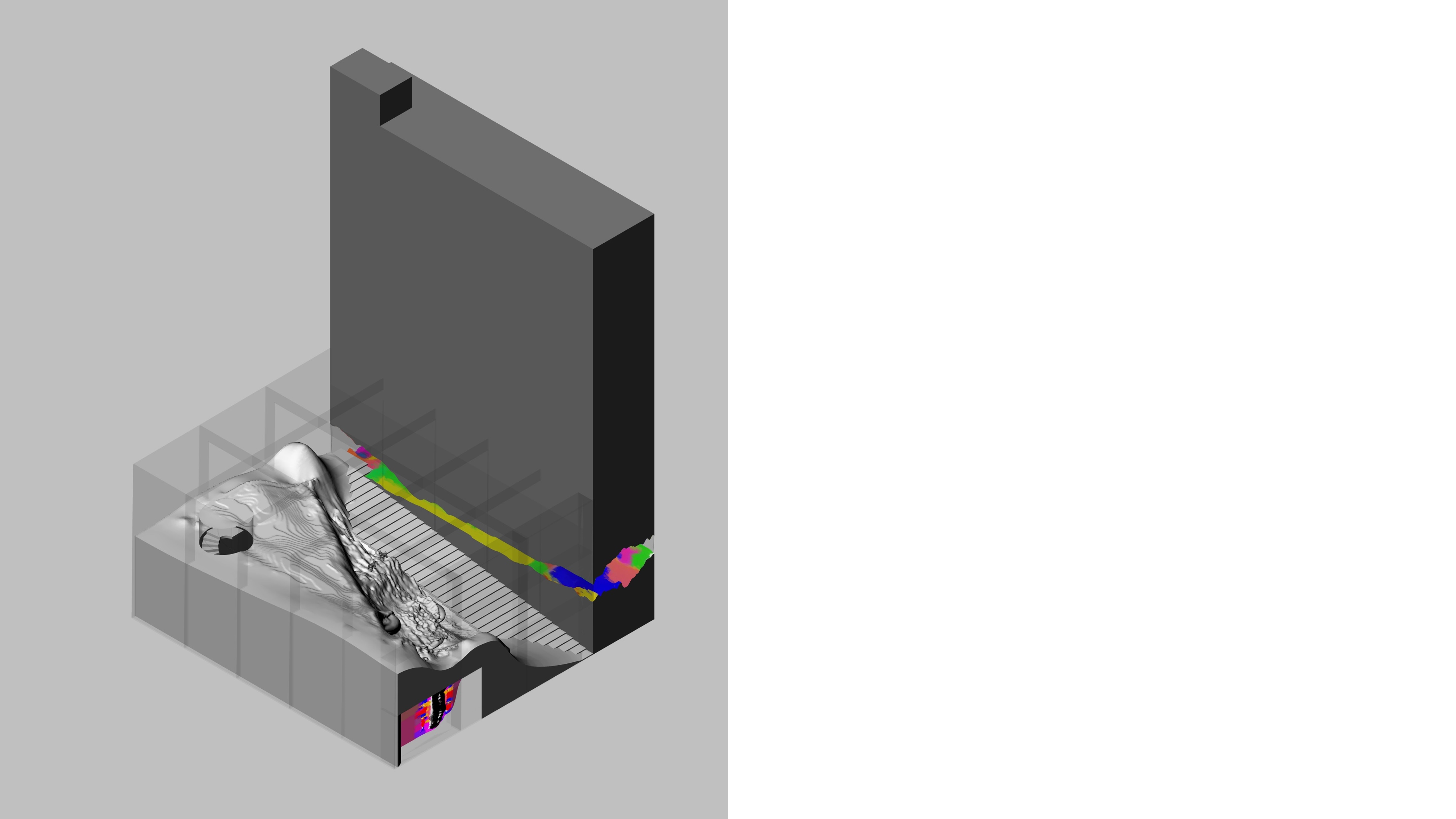
Isometric View
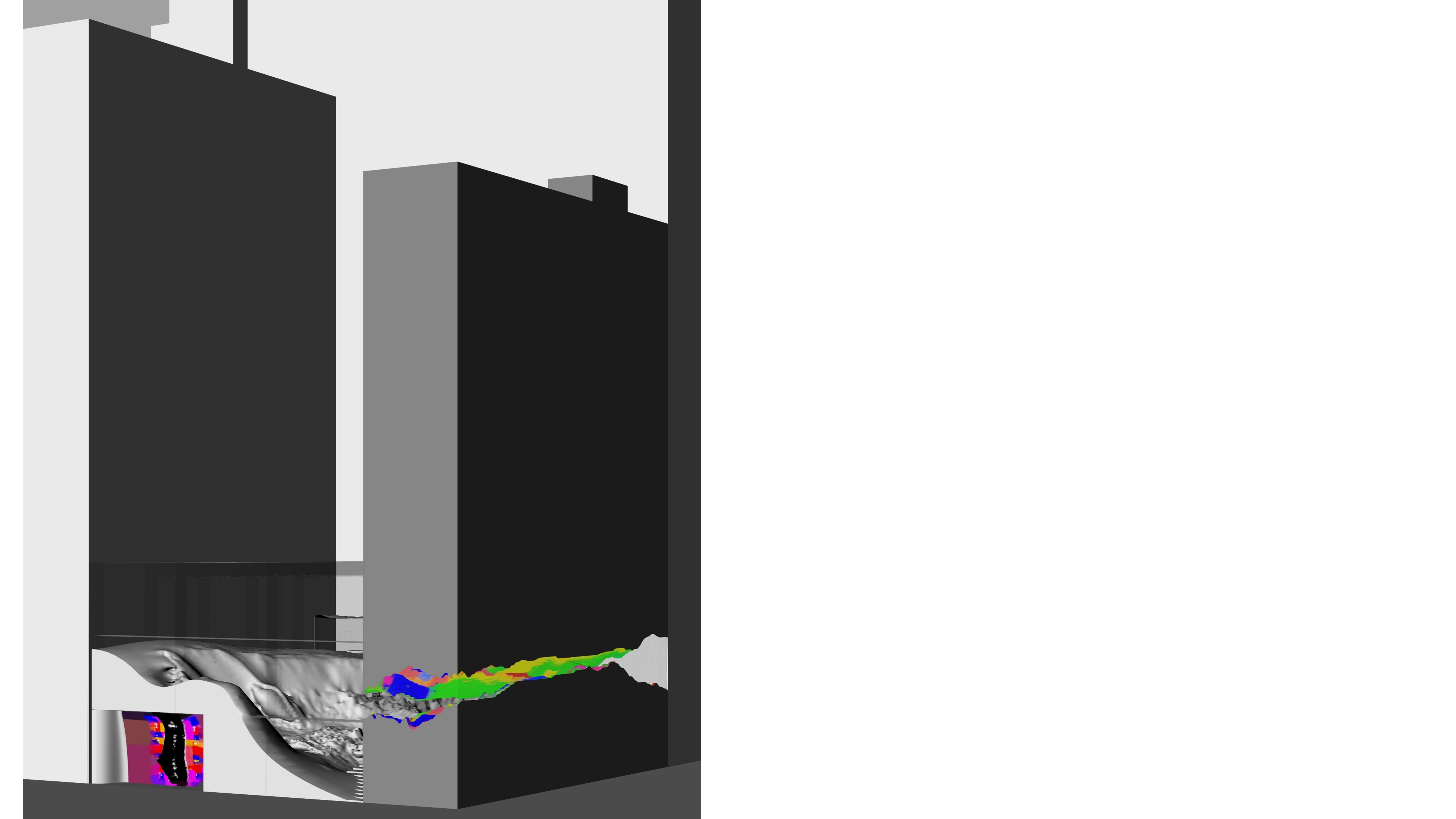
Perspective View

Plan





